مقدمه
از زمانهای قدیم و در پی حوادث و وقایع طبیعی، بشر همواره بهدنبال راهکارهایی برای جلوگیری یا کنترل این وقایع بوده است. زمینلرزه یکی از این حوادث طبیعی است که وقوع آن همواره تلفات جانی و مالی سنگینی بههمراه داشته است. زمان، مکان و بزرگای زمینلرزه سه پارامتر اصلی زمینلرزه هستند که برای کنترل و کمینه کردن تلفات آن باید برآورد خوبی از مقادیر آنها در دست باشد (
ارجمند و همکاران، 1395). زمینلرزه مخاطره طبیعی، ناگهانی، با منشأ زمینی است و بهلحاظ قدرت و حوزه تخریب وسیع بوده و نیز غیرقابلپیشبینی بودن و زمان بسیار کوتاه وقوع آن از اهمیت ویژهای برای جوامع بشری برخوردار است (
غلامی و شکوهی بیدهندی، 1401). زمینلرزه حالت خاصی از تغییر شکل تودههای سنگی است که در آن پدیدههای گـسیختگی در مقیاس متفاوت رخ میدهد، یا هر نوع لرزش زمین در اثر عبور امواج لرزهای را زلزله گویند (
گالکینا و گرافیوا، 2019). عوامل متعدد طبیعی و انسانی باعث بروز زمینلرزه در سطح زمین میشوند که از آن جمله میتوان به لرزشهای ایجادشده ناشی از فعالیت آتشفشانی و فعالیت گسل و لرزشهای مصنوعی در اثر انفجارهای اتمی که جزء عامل انسانی است، اشاره کرد (
اسفندیاری و همکاران، 1392). وجود یا عدم وجود گسلها و شکستگیهای زمین و فعالیتهای اخیر آنها و جوان بودنشان ازجمله شاخصهایی هستند که میتوانند در فعالیتهای آتی آن اثرگذار باشند. درواقع، رابطه گسل و زمینلرزه دوطرفه است، یعنی گسلهای فراوان در یک منطقه سبب بروز زمینلرزه میشوند (
اسفندیاری و همکاران، 1396). پس میتوان گفت مهمترین عامل زمینساختی ایجادکننده زمینلرزهها، گسلها هستند و براساس ا ینکه کدامیک از دیوارههای گسل بر دیواره دیگر بلغزد، سازوکارهای گسلش متفاوت خواهد بود (
خدادادیجید و پورزینلی، 1401). زمینلرزه یک مخاطره طبیعی است که در اثر حرکت صفحات تکتونیکی زمین بهدلیل آزاد شدن انرژی داخلی قابلتوجه آن ایجاد میشود. یک زمینلرزه متوسط با بزرگای بیش از 6 ریشتر میتواند تلفات گسترده و خسارات زیرساختی هنگفتی را که میلیاردها دلار هزینه دارد، وارد کند. اما اگر بتوان وقوع زمینلرزه را پیشبینی کرد، میتوان شدت تخریب را به حداقل رساند. یک روش کامل پیشبینی زمینلرزه باید دارای سه نوع اطلاعات باشد: بزرگی، مکان و زمان وقوع (
البنا و همکاران، 2020). پیشبینی زمینلرزه را میتوان به فرایند کوتاهمدت و بلندمدت طبقهبندی کرد. پیشبینی کوتاهمدت بسیار پیچیده است، زیرا زمینلرزهها را ظرف چند روز یا چند هفته پیش از وقوع آنها پیشبینی میکند. بنابراین باید دقیق باشد. معمولاً برای تخلیه یک منطقه قبل از وقوع زمینلرزه از پیشبینیهای کوتاهمدت استفاده میشود. از سوی دیگر، زمینلرزههای بلندمدت براساس ورود دورهای زمینلرزهها پیشبینی میشوند که حاوی اطلاعات کمی است. بااینحال، آنها میتوانند به تنظیم استانداردهایی برای کدهای ساختمانی و طراحی طرحهای واکنش در بلایا کمک کنند (
البنا و همکاران، 2020). همچنین پیشبینی زمینلرزه باید شامل زمان، مکان، بزرگی، احتمال و دلیل وقوع آن نیز باشد. هدف از پیشبینی زمینلرزه، کمک به سازمانهای کنترل بلایا در آمادگی برای زمینلرزه است. هنگامی که یک زمینلرزه قوی پیشبینی میشود، مدیران کنترل بلایا باید برای انجام اقدامات پیشگیرانه هشدار داده شوند. در آمادگی در برابر فاجعه، تصمیمات و فعالیتها بر پیشگیری از خسارات متمرکز است. بهطور آشکار، انواع تکنیکهای پیشبینی زمینلرزه برای کاهش خسارات به کار گرفته شده است (
بهاتیا و همکاران، 2023).
ازآنجاییکه ایران روی کمربند لرزهخیز آلپ هیمالیا قرار دارد و بهعنوان یکی از بخشهای جوان و در حال کوهزایی به شمار میرود، جزو کشورهای لرزهخیز است، بهطوریکه زمینلرزههای فاجعهباری در سالهای اخیر باعث تلفات جانی و مالی فراوان شدهاند (
بربریان و کینگ، 1981). مجاورت با صفحه عربستان و فشار این صفحه بر صفحه ایران باعث شکستگی گسلها شده و همین امر به زمینلرزههای بسیار شدید در ایران منجر شده است (
حیدری مظفر و تاجبخشیان، 1401). در بخش شاهرود شهرستان خلخال، وجود سازندهای زمینشناسی با مقاومت ناهمگن، استقرار شهر روی یک دشت آبرفتی با مقاومت کمتر نسبت به سنگ بستر ضخیم لایه و احاطه شدن توسط گسلهای متعدد سبب شدهاند تا این شهر نسبت به مخاطره زمینلرزه پتانسیل بالایی داشته باشد. همچنین قرارگیری بخش شاهرود در زون چینخورده البرز غربی و آذربایجان سبب شده که تحت تأثیر فازهای کوهزایی گسلهای مختلفی در منطقه ایجاد شود که از مهمترین این گسلها میتوان به گسل تالش، گسل نئور و گسل شاهرود کلور اشاره کرد. مطالعه و ارزیابی بخش شاهرود بهلحاظ لرزهخیزی و پیشبینی بزرگای زمینلرزه یکی از ضرورتهای برنامهریزی است. پیشبینی بزرگای زمینلرزه از اهمیت بالایی برخوردار است، زیرا این پیشبینیها امکان حفظ امنیت عمومی، کاهش خسارات، توسعه زیرساختهای مقاوم و جلوگیری از از دست رفتن زندگیها و داراییها را فراهم میکنند. بهعلاوه، این امر پیشرفت علمی و توسعه فناوری را تشویق میکند. بهطور خلاصه، پیشبینی بزرگای زمینلرزه نهتنها برای ما اطلاعات لازم را فراهم میکند، بلکه به ما امکان میدهد از این اطلاعات برای مدیریت بهتر بحرانهای زمینلرزه و حفظ امنیت و سلامتی افراد استفاده کنیم.
نوآوری این پژوهش نسبت به سایر مطالعات انجامشده این است که از مدل نوین شبکه عصبی برای پیشبینی بزرگای زمینلرزه استفاده شده است که در زمینه پیشبینی و حل مسائل پیچیده عملکرد خوبی دارد. هدف از پژوهش حاضر پیشبینی بزرگای زمینلرزه احتمالی در بخش شاهرود شهرستان خلخال با استفاده از شبکه عصبی است.
پیشینه تحقیق
پیرامون موضوع پیشبینی زمینلرزه با استفاده از روشهای مختلف مطالعات متعددی در داخل کشور و خارج از آن صورت گرفته است که بهطور مختصر به برخی از آنها اشاره میشود.
خیری و همکاران (1395)، به پیشبینی بزرگی زمینلرزه گسل تبریز با استفاده از رگرسیون چندجملهای پرداختند. آنها در این پژوهش رابطهای برای این مدل ارائه دادند که در آن زمان وقوع زمینلرزهها مهمترین متغیر مستقل برآوردکننده بزرگی است و با واردکردن دادههای لرزهای جدید میتوان بزرگی زمینلرزه را با کمترین خطا پیشبینی کرد.
حیاتی و همکاران (1395)، به پیشبینی محل وقوع زمینلرزه احتمالی در استان خراسان رضوی با استفاده از روش شبکه عصبی مصنوعی پرداختند. آنها به این نتیجه رسیدند که میانگین بزرگی و عمق زمینلرزههای اتفاقافتاده در این استان بهترتیب 4/6 و 20/96 کیلومتر بوده است و بیشترین احتمال وقوع زمینلرزه در منطقه مرکزی متمایل به غرب استان (شهرستان کاشمر و جنوب شرق شهرستانهای سبزوار و بردسکن) و در منطقه جنوب شرق استان (شهرستان خواف) با احتمال 30 درصد بالاتر نسبت به سایر مناطق پیشبینی شده است.
ارجمند و همکاران، (1395)، به پیشبینی بزرگای زمینلرزه با استفاده از شبکه عصبی پرسپترون چندلایه پرداختند. نتایج پژوهش آنها نشان داد شبکه عصبی پرسپترون چندلایه توانایی بالایی در پیشبینی بزرگای زمینلرزه دارد و گزینه بسیار مناسبی برای این منظور است.
سلطانپور و همکاران (1397)، به ارزیابی ریسک زمینلرزه در شمال غرب تهران با استفاده از فرایند تحلیل سلسلهمراتبی (مطالعه موردی منطقه 22) پرداختند. در نتایج مطالعه آنها با در نظر گرفتن آسیبپذیری و خطر و جمعیت در منطقه مشخص شد ریسک زمینلرزه منطبق با نقاط جمعیتی در منطقه است و هرچه از پهنههای با جمعیت بالا دور میشویم ریسک کمتر میشود. بنابراین کنترل جمعیتپذیری و ساختمانسازی در منطقه از اعتبار بالایی در کاهش ریسک برخوردار است.
دانا و همکاران (1399)، به ارزیابی آسیبپذیری نواحی منطقه 8 شهرداری تهران در برابر زمینلرزه با استفاده از روش AHP پرداختند. نتایج پژوهش آنها نشان داد ناحیه 3 آسیبپذیرترین ناحیه است و قسمت عمده بافتهای فرسوده در این ناحیه وجود دارد. از نظر آسیبپذیری، ناحیه 3 با ضریب اهمیت 51/39 در رتبه اول، ناحیه یک با ضریب اهمیت 27/19 در رتبه دوم و ناحیه 2 با ضریب اهمیت 21/42 در رتبه سوم قرار دارد.
پیریزاده و پیریزاده (1400)، به ارزیابی و تحلیل کاربرد هوش مصنوعی در تحلیل دادههای لرزهشناسی (مطالعه موردی: دادههای پیشنشانگرها) با استفاده از روشهای یادگیری ماشینی و یادگیری عمیق پرداختند. نتایج مطالعه آنها نشان داد رویکرد مبتنی بر یادگیری عمیق با میانگین دقت متعادل 81/2 درصد و 59/3 درصد بهترتیب بر روی دادههای آموزشی و آزمون، عملکرد کاملاً بهتری در مقایسه با شبکههای عصبی بازگشتی معمولی در طبقهبندی مقادیر اوج شتاب زمین از خود بر جای گذاشته است و میتوان با اصلاح کردن تابع هزینه شبکههای بازگشتی عمیق بهکمک رویکرد حساس به هزینه، چالش عدم تعادل کلاس دادههای لرزهای را نیز بهخوبی کنترل کرد.
کاظمی و همکاران (1400)، به ارزیابی و تخمین سریع بزرگا و فاصله رومرکزی زمینلرزه برای منطقه البرز با استفاده از روش B-Δ پرداختند. ایشان در این پژوهش روابطی را جهت تخمین بزرگا و فاصله مرکزی ارائه دادند که این روابط میتوانند بهعنوان روابطی قابلاطمینان و مناسب در سامانه هشدار سریع منطقه البرز به کار گرفته شوند.
احمدی نمین و کاظمیان (1402)، به مطالعه رابطه بین زمینلرزه و آبوهوا در زمینلرزههای اخیر ایران با استفاده از روش توصیفی تحلیلی پرداختند. نتایج پژوهش آنها حاکی از آن است که در زمان وقوع زمینلرزه در اکثر عوامل آبوهوایی تغییر مشاهده شده و بین آنها رابطه وجود دارد.
یازرلو و بای (1402)، به پیشبینی زمینلرزههای القایی ناشی از سدسازی بهوسیله شبکه عصبی مصنوعی پرداختند و روشهایی را برای پیشبینی زمینلرزه القایی ارائه دادند.
همچنین از مطالعات خارجی در این مورد میتوان به موارد زیر اشاره کرد:
گالکینا و گرافیوا، 2019)، به ارزیابی و تحلیل روشهای یادگیری ماشین برای پیشبینی زمینلرزه پرداختند. آنها در مطالعه خود روند دادهها، ویژگیها، میزان کامل بودن و معیارهای اندازهگیری عملکرد را برای این مطالعات مشاهده کردند. آنها متوجه شدند که این مطالعات در پیشبینی زمینلرزههای نادر اما مهمتر با مشکلاتی روبهرو هستند.
فنگ و فاکس (2020)، در پژوهشی تحت عنوان پیشبینی زمینلرزههای شدید مکانی ـ زمانی در جنوب کالیفرنیا، یک روش مدلسازی عمیق مشترک برای پیشبینی زمینلرزه را پیشنهاد کردند که این روش در مقایسه با برخی از شبکههای عصبی مکرر از نظر پیشبینی شوکهای بزرگ برای زمینلرزههای جنوب کالیفرنیا، امیدوارکننده بود.
البنا و همکاران (2020)، به بررسی کاربرد هوش مصنوعی در پیشبینی زمینلرزه پرداخته و با پوشش تمام تکنیکهای مبتنی بر هوش مصنوعی موجود در پیشبینی زمینلرزه، شرحی از روشهای موجود و تحلیل مقایسهای عملکرد آنها ارائه دادهاند.
اپریانی و همکاران (2021)، به تخمین بزرگی زمینلرزه براساس یادگیری ماشین (کاربرد در سیستم هشدار اولیه زمینلرزه) پرداختند. نتایج حاصل از پژوهش آنها حاکی از آن بود که شکل موج را میتوان با مدلهای شبکه عصبی عمیق مدلسازی کرد. همچنین آنها در رابطه با تخمین بزرگی زمینلرزه پیشنهاد کردند مدلسازی خام لرزهای با استفاده از طبقهبندی DNN با مجموعه داده بزرگتر بهتر است و در رابطه با مجموعه داده نسبتاً کوچک، مدلسازی با استفاده از الگوریتم جنگل تصادفی میتواند گزینه دیگری باشد.
بهاتیا و همکاران، (2023)، به پیشبینی زمینلرزه در زمان واقعی مبتنی بر هوش مصنوعی پرداختند و به این نتیجه رسیدند که براساس شبیهسازی تجربی، اثربخشی افزایشیافته برای چارچوب ارائهشده از نظر عملکرد طبقهبندی دقت (92/52 درصد)، حساسیت (91/72 درصد) و ویژگی (91/01 درصد) بوده است.
سعد و همکاران (2023)، در پژوهشی تحت عنوان پیشبینی زمینلرزه با استفاده از دادههای بزرگ و هوش مصنوعی، چارچوبی را برای پیشبینی زمینلرزه در زمان واقعی طراحی کرده و آن را در مناطق لرزهزا در جنوب غربی چین آزمایش کردند.
موسوی و بروزا (2023)، به بررسی یادگیری ماشین در زلزلهشناسی پرداختند و در پژوهش خود تکنیکهایی را برای زلزلهشناسی ارائه دادند.
منطقه موردمطالعه
در تقسیمات سیاسی استان اردبیل، شهرستان خلخال با محوریت شهر خلخال بهعنوان یکی از 12 شهرستان استان، در قسمت جنوب اردبیل قرار دارد. شهرستان خلخال از ناحیه شرق به استان گیلان، از قسمت غرب به آذربایجان شرقی، از جنوب به استان زنجان و از شمال به بخش کوثر منتهی میشود. فاصله بخش مرکز شهر خلخال تا استان اردبیل، ۱۱۶ کیلومتر است. از لحاظ تقسیمات سیاسی، شهرستان خلخال از سه بخش مرکزی، شاهرود و خورشرستم تشکیل شده است. ناحیه شاهرود، جزو مناطق تابعه شهرستان خلخال، با مختصات جغرافیایی ۳۱ درجه و ۴۸ دقیقه طول شرقی و ۳۴ درجه و ۳۷ دقیقه عرض شمالی است (
تصویر شماره 1).
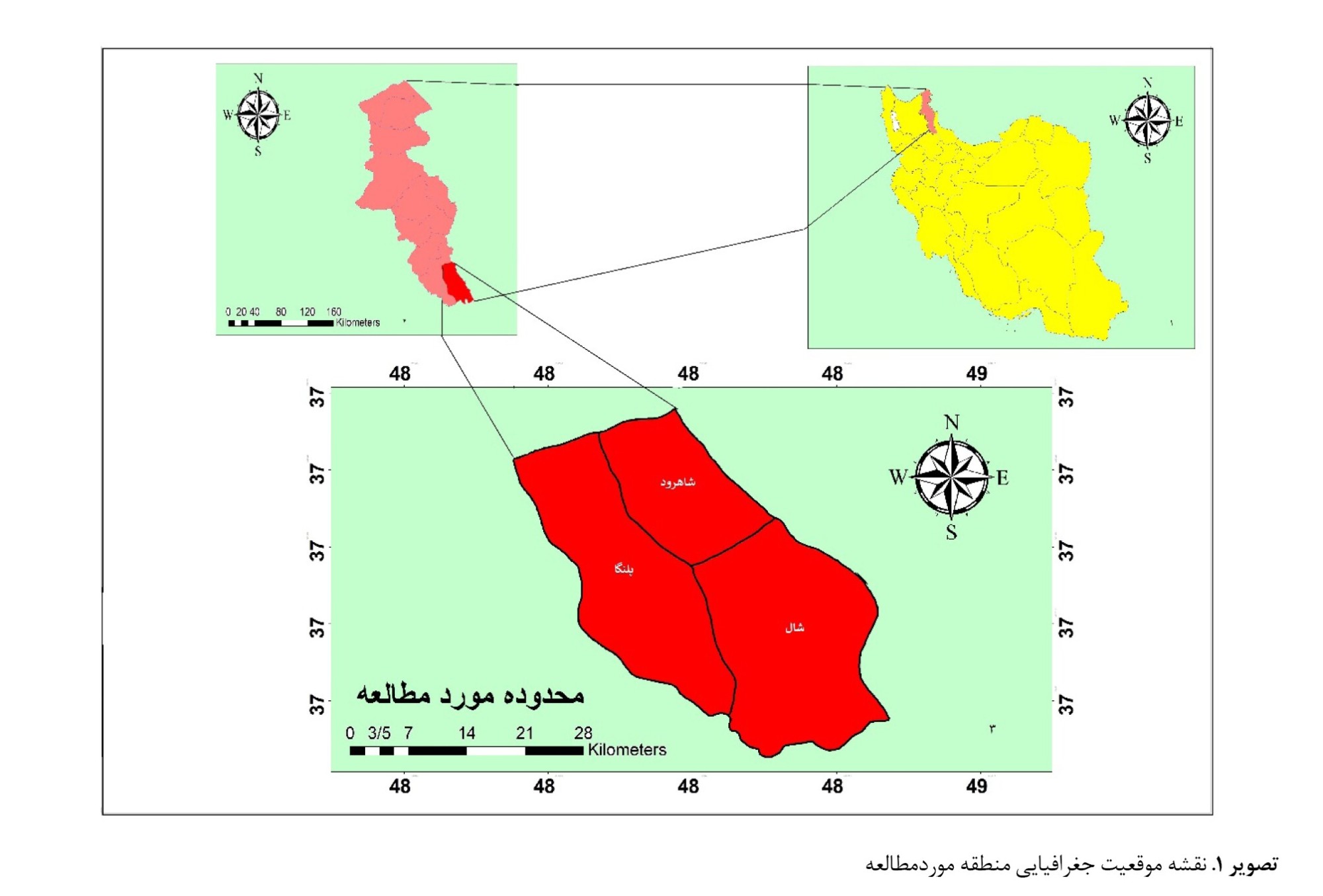
این منطقه در جنوب شرقی شهرستان خلخال و در نزدیکی رشتهکوه تالش و کوه آقداغ واقع شده و ارتفاع متوسط آن از سطح دریا ۱۵۵۰ متر است (
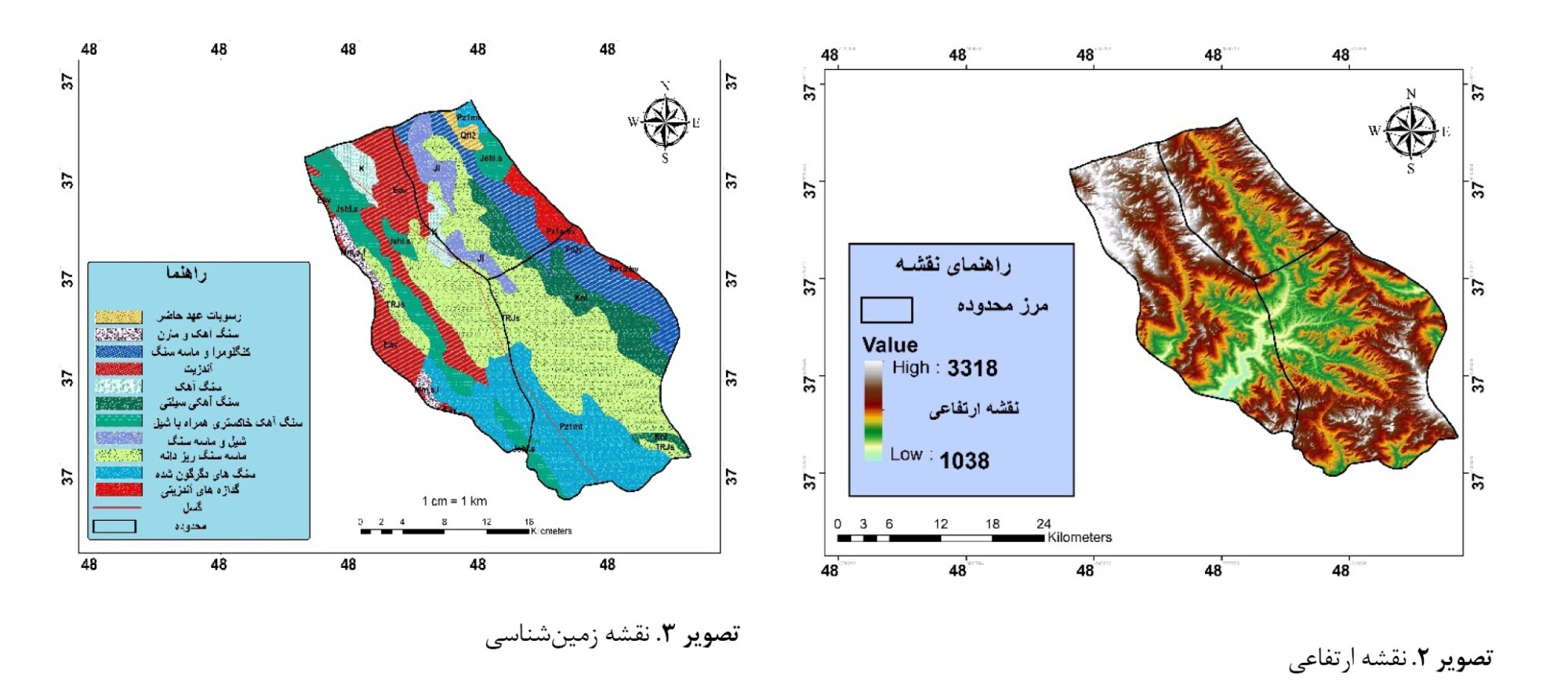
تصویر شماره 2).بخش شاهرود به محوریت شهر کلور دارای سه دهستان بزرگ شامل دهستان شاهرود، پلنگا و شال است که در کل دارای 47 آبادی است. از ویژگیهای بخش شاهرود میتوان به کوهستانی بودن آن اشاره کرد، بدینجهت که ارتفاعات تالش در قسمت شرقی و ارتفاعات پلنگا و آقداغ در قسمت جنوبی سبب چهره کوهستانی بخش شاهرود شده است (
تصویر شماره 3). همچنین بهلحاظ تکتونیک، منطقه موردمطالعه در دوران زمینشناسی تنشهای زیادی را به خود دیده که آخرین و تأثیرگذارترین آنها حرکت کوهزایی آلپی است که سبب شکلگیری ارتفاعات شامل چینخوردگیها منطقه شده و تحت تأثیر این فعالیتهای زمینساختی گسلها و شکستگیهای مختلفی در منطقه ایجاد شده که تأثیر زیادی در فعالیتهای لرزهخیزی دارند. قرارگیری بخش شاهرود در ناحیه شرقی ارتفاعات تالش سبب شده بهلحاظ زمینشناسی و ژئومورفیک، خصوصیات زون البرز غربی و آذربایجان را در خود داشته و از تنوع بالای فرایندهای زمینشناسی و ژئومورفیک برخوردار باشد. همچنین بهلحاظ سنگشناسی و چینهشناسی نیز قدیمیترین سنگهای استان اردبیل در قسمت جنوب خلخال دیده میشود که از پرکامبرین بالا تا دوران چهارم پراکنده است. این پراکندگی بهنحوی است که در بخش شاهرود تا شهر خلخال هر سه نوع سنگ آذرین، رسوبی و دگرگون دیده میشود (
تصویر شماره 3).
 روش
روش
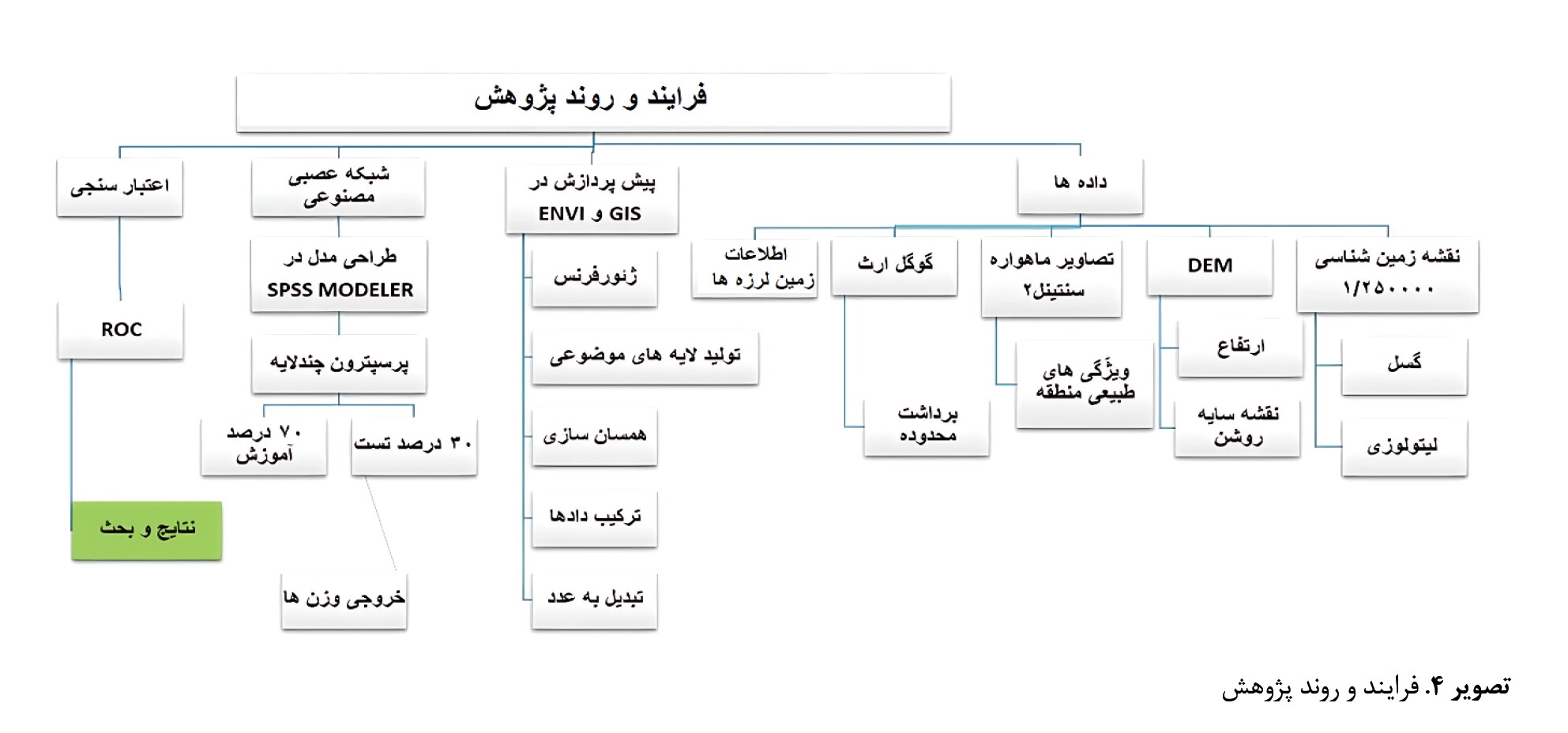
در پروسه انجام این پژوهش از دادهها و اطلاعات مختلفی استفاده شد که شامل نقشه زمینشناسی شهرستانهای رضوانشهر، خلخال و ماسوله با مقیاس 1:100000 بوده و نقشه مربوط به گسلها و سازندهای زمینشناسی از این نقشه اخذ شده است. از مدل رقومی ارتفاعی با قدرت تفکیک مکانی 12/5 مربوط به ماهواره آلوس ـ پالسار و همچنین از تصاویر ماهوارهای سنتینل 2 برای شناسایی ویژگیهای زمینشناسی استفاده شد. برای ویژگیهای مختلف زمینلرزهها از دادههای لرزهخیزی در بازه 30ساله مؤسسه ژئوفیزیک دانشگاه تهران و دادههای جهانی سازمان زمینشناسی آمریکا استفاده شد که شامل تاریخ وقوع، بزرگی، عمق کانونی و مختصات جغرافیایی است. انتخاب بازه 30ساله بهخاطر وجود دادههای کامل بوده است و دادههای بیشتر از بازه 30ساله اکثراً ناقص بودند، بنابراین از انتخاب آنها صرف نظر شد. تمام دادههای مورداستفاده برای آمادهسازی در مرحله اول وارد نرمافزار جیآیاس نسخه 1/7/10 شد و پردازش مقدماتی روی تمام لایهها انجام گرفت. سپس بعد از اتمام پیشپردازش کار مدلسازی در نرمافزار SPSS Modeler نسخه 18 انجام شد (
تصویر شماره 4).
 شبکه عصبی پرسپترون چندلایه
شبکه عصبی پرسپترون چندلایه
مککالوک و همکاران در اوایل دهه 1940 روش شبکه عصبی را پایهگذاری کردند. بهطورکلی، شبکه عصبی یک ابزار پیشبینی برای ساخت یک مدل ریاضی از یک سیستم ناشناخته است. هوش مصنوعی یکی از مشهورترین رشتههای علم است که یکی از شناختهشدهترین آن، مدل شبکههای عصبی پرسپترون چندلایه است (
گندمی و همکاران، 1398). اجزای کلیدی در هوش مصنوعی شبکههای عصبی هستند که در پردازش تصویر و بینایی کامپیوتری ادغام شدهاند. ادغام شبکههای عصبی و سایر ابزارهای محاسباتی ریاضی در علوم رایانه میتواند مفید باشد. شبکه عصبی مصنوعی یک سازوکار محاسباتی است که قادر است با گرفتن اطلاعات و محاسبه کردن آنها، یک سری اطلاعات جدید ارائه دهد. در شبکه عصبی مصنوعی سعی بر آن است که ساختاری مشابه ساختار بیولوژیکی مغز انسان و شبکه اعصاب بدن ساخته شود تا همانند مغز، قدرت یادگیری، تعمیمدهی و تصمیمگیری داشته باشد و یک پهنهبندی از یک فضای چندمتغیره با اطلاعات دریافتی را به وجود آورد (
لی و همکاران، ۲۰۰۶). شبکههای عصبی اطلاعات را از لایههای ورودی دریافت میکنند و با وزنهای مختلف به هم متصل میشوند. اطلاعات واردشده از لایه ورودی به لایه میانی منتقل میشوند، جایی که گرهها عملیات پردازش را انجام میدهند. لایه میانی عملیات پیچیدهتری را انجام میدهد. گرهها اطلاعات را از لایههای ورودی دریافت کرده و با استفاده از وزنهای خود، پردازشهای مختلفی را اجرا میکنند. نتیجه این پردازش بهصورت لایه خروجی از شبکه حاصل میشود. شبکههای عصبی مصنوعی پرسپترون چندلایه شامل یک یا چند لایه میانی هستند که نورونهای این لایه بهعنوان نورونهای مخفی شناخته میشوند. افزودن چندین لایه میانی باعث افزایش توانایی شبکه در تحلیلهای با پیچیدگی بالاتر میشود (
هاگان و همکاران، 2014). این الگوریتمها بهعنوان شبکههای نظارتشده شناخته میشوند؛ به این معنا که نتایج پیشبینیشده توسط مدل را میتوان با مقادیر شناختهشده متغیرهای هدف مقایسه کرد. یکی از مزایای اصلی شبکههای عصبی در مقایسه با تکنیکهای آماری کلاسیک، انعطافپذیری و عدم وجود مفروضات توزیعی آنهاست (
یان و همکاران، 2023). بهعنوانمثال، شبکههای عصبی را میتوان برای پیشبینی نتایج قطعی و پیوسته استفاده کرد. بااینحال، مشکل این است که شبکههای عصبی اغلب میتوانند بهسختی تفسیر شوند، زیرا میتوانند مدلهای بسیار پیچیده با لایههای متعدد تولید کنند. یک شبکه عصبی یک پردازشگر موازی توزیعشده انبوه است که تمایل طبیعی برای ذخیره دانش تجربی و در دسترس قرار دادن آن برای استفاده دارد (
المغربی و همکاران، 2023). تعلیم شبکه عصبی پیشخور شامل اختصاص وزن بین نورونها بوده و در هر بار وزندهی، مجموعهای از ورودیها و خروجیهای مطلوب بهعنوان نمونه به خدمت گرفته میشوند. الگوهای احتمالاتی با یکدیگر برابر در نظر گرفته میشوند؛ به این معنی که هیچ الگویی نسبت به سایر الگوها از اهمیت بیشتری برخوردار نیست (
رامدانی و همکاران، 2022). در ابتدا، وزن بین نورونها بهصورت تصادفی تعیین میشود و سپس الگوی ارائهشده به شبکه با نتایج مطلوب مقایسه میشود. مسلماً خروجیهای اولیه به نتایج مطلوب شبیه نبوده و دارای خطای نسبی نسبت به فاصله اقلیدسی بین خروجی محاسبهشده و نتایج مطلوب هستند. از بین کمترین میانگین خطا، وزنها مطابق با میزان خطا اصلاح شده و میزان آنها کاهش مییابد. با چندین مرحله تکرار، خروجی شبکه به سمت خروجی مطلوب متمایل خواهد شد.
طبقهبندیکننده MLP از الگوریتم فرمول شماره 1 برای محاسبه ورودیهایی که یک گره منفرد دریافت میکنند، بهره میبرد (
منهاج، ۱۳۸۸).
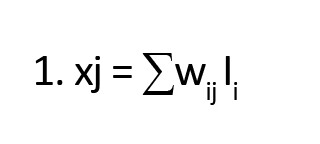
در رابطه فوق x ورودی است که نورون منفرد j دریافت میکند، w
ij اوزان بین نورون i و نورون j را نشان میدهد و خروجی نورون I
i متعلق به لایه فرستنده، لایه ورودی یا مخفی است. خروجی حاصل از نورون j از فرمول شماره 2 حاصل میشود (
منهاج، ۱۳۸۸).
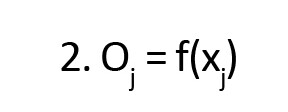
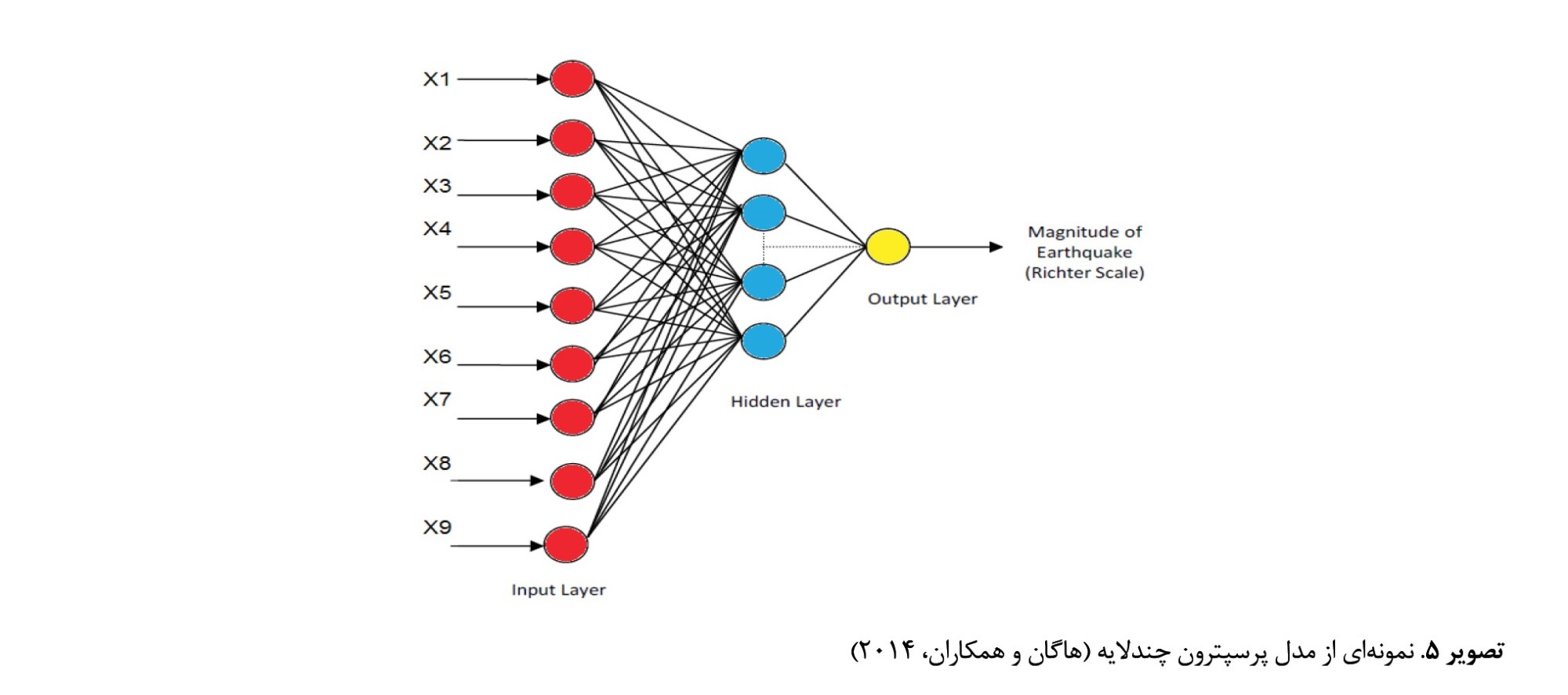
تابع f معمولاً یک تابع سیگموئیدی غیرخطی است. در این پژوهش لایههای ورودی متناظر با لایههای اطلاعاتی سیستم اطلاعات جغرافیایی آماده شده و در لایه خروجی نیز معادل پیشبینی بزرگای زمینلرزه در محدوده موردمطالعه است (
تصویر شماره 5).
 یافتهها
یافتهها
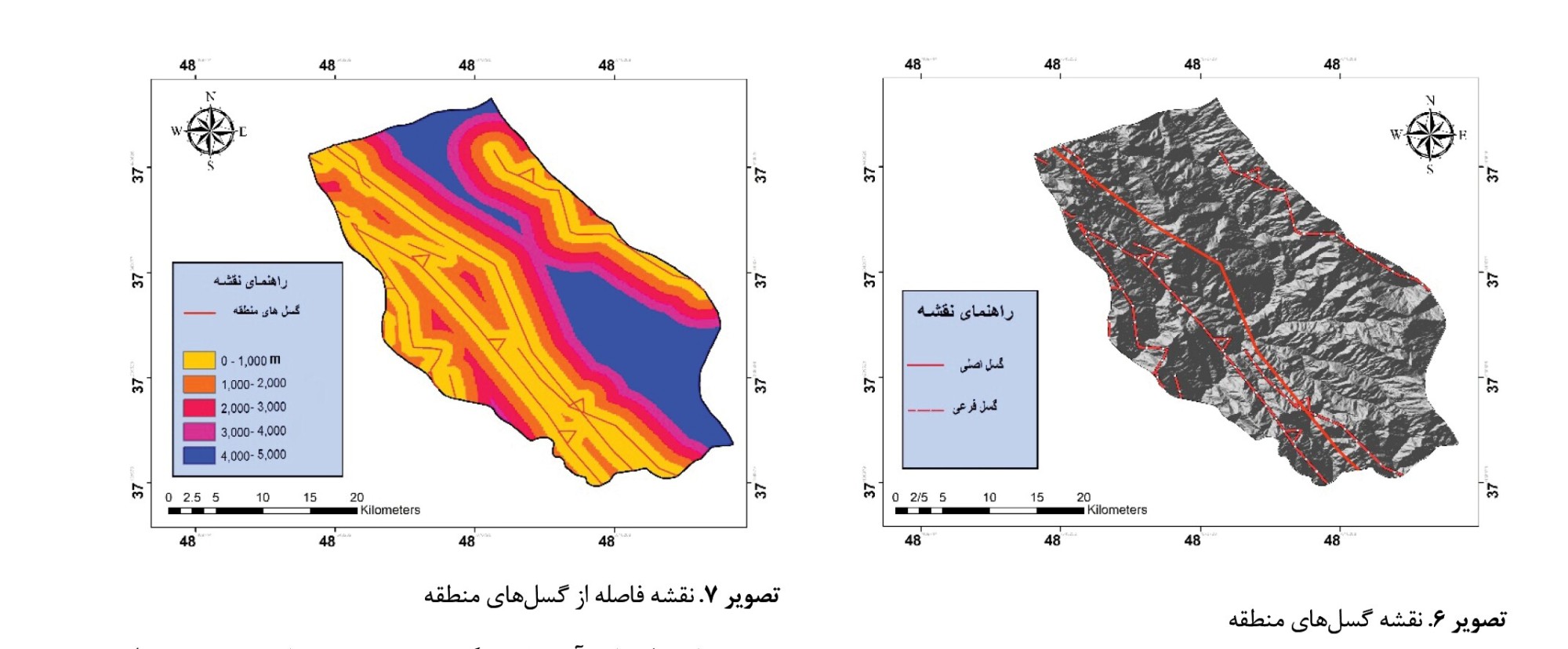
باتوجهبه نقشه زمینشناسی منطقه، گسلهای شناختهشده را میتوان به دو دسته تقسیمبندی کرد:
گسلهای داخل محدوده
از اصلیترین گسلهای داخل منطقه میتوان به گسل هروآباد یا شاهرود چای اشاره کرد (
تصویر شماره 6). گسل هروآباد با طولی بیش از ۱۸۸ کیلومتر و جهت امتدادی تقریباً شمال به جنوب، در نزدیکترین نقطه به فاصله ۱۰کیلومتری از منطقه عزیزآباد قرار دارد. نحوه تشکیل آن بهگونهای است که بلوک شرقی نسبت به بلوک غربی به بالا برآمده است. این سازوکار باعث جابهجایی مارنها و تجمع رسوبات آواری در منطقه کربیتاسه روی آتشفشانهای پالئوژن شده است. انحنای این گسل از میان رودخانه عبور میکند، بنابراین میتوان گفت سیستم رودخانه از سیستم گسل پیروی میکند. این گسل سبب بالاآمدگی بلوک غرب شده و در پای این گسل فروافتادگی ایجاد کرده است که از میان آن شاهرود چای عبور میکند (
سیارپور، 1378). همچنین گسلهای فرعی دیگری در محدوده هستند که حاصل تکتونیک و نیروهای فشاری بوده و برخی از آنها دارای ابعاد کوچک و جزو گسلهای محلی هستند. از سایر گسلهای منطقه میتوان به گسلهای اصلی و بزرگ که فعالیت آنها دارای قدرت بیشتر است اشارهکرد که شامل گسلهای زیر است:
گسل گیوی
این گسل دارای جهت شمال به جنوب بوده و طولی به اندازه تقریباً ۱۴۲ کیلومتر دارد. این گسل مرز بین رسوبات مزوزوئیک و سنگهای آتشفشانی در جهت شرق و رسوبات نئوژن در جهت غرب را به وجود آورده است. متأسفانه، جزئیات دقیق درمورد سن یا تاریخچه لرزهای این گسل در دسترس نیست، اما مرکز زمینلرزههای تاریخی در سالهای ۱۸۶۳ و ۱۸۰۶ بهطور دقیق در همین گسل قرار داشته است. این وضعیت میتواند احتمال جنبشی بودن این گسل را تقویت کند. به نظر میرسد زمینلرزه تاریخی خلخال، بهعلت عملکرد این گسل اتفاق افتاده و ویرانیها ناشی از حرکات این گسل باشد.
گسل ماسوله
در بخش جنوبی گسل شرق اردبیل، گسل ماسوله شروع میشود و به سمت جنوب شرقی ادامه مییابد. مکانیسم ایجاد این گسل از طریق فرایند راندگی صورت میپذیرد که در آن بلوک خاوری نسبت به بلوک باختری بالا میرود.
گسل کلور
در ناحیهای از رشتهکوههای البرز غربی که جهت امتدادی آن از شمال به جنوب تغییر میکند، شکل گرفته است. طول این گسل برابر با حدود ۶۳ کیلومتر است. مکانیسم ایجاد این گسل بهصورت معکوس اتفاق افتاده است (
تصویر شماره 7).
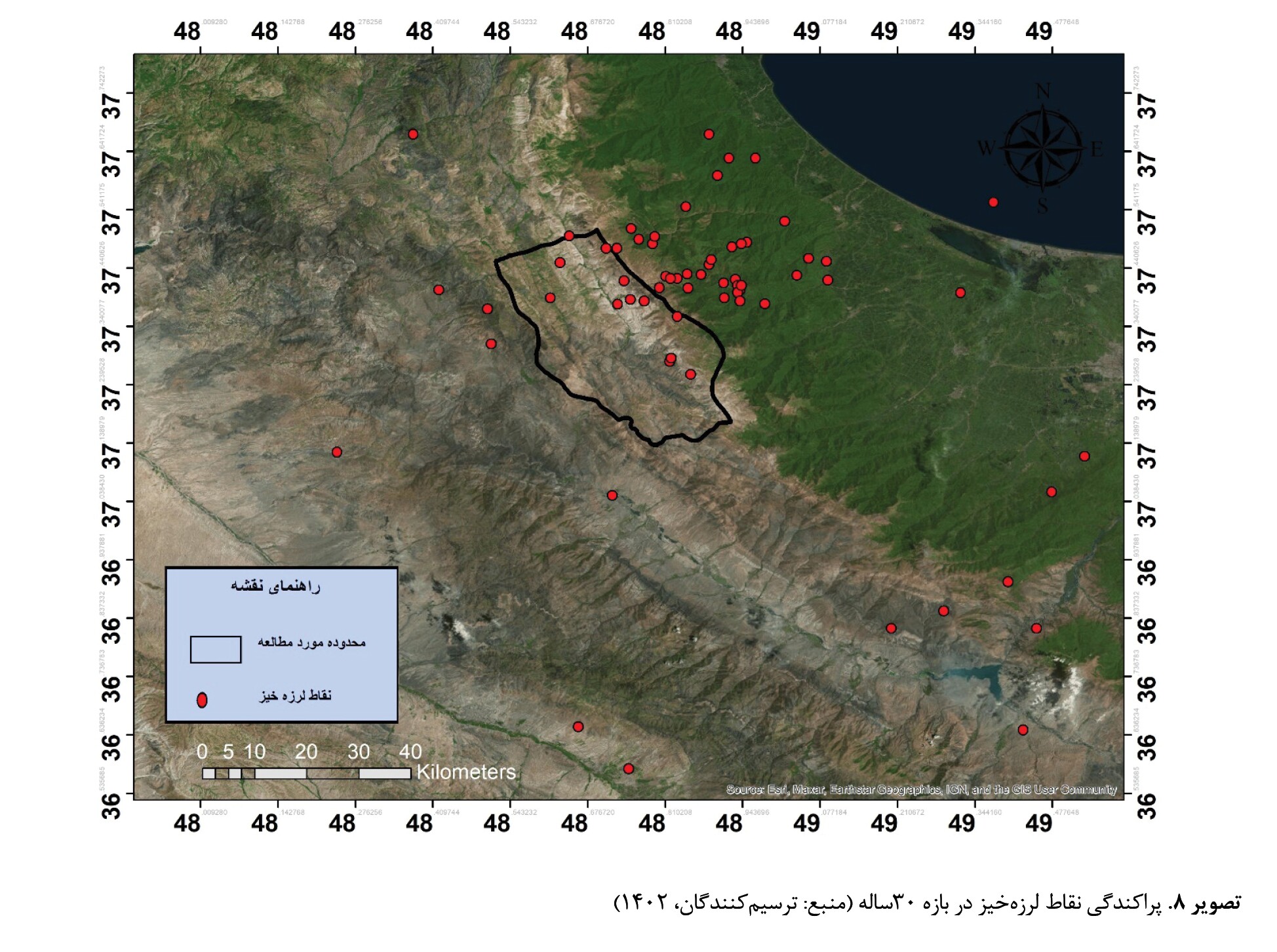
پراکندگی نقاط لرزهخیز در بازه 30ساله در
تصویر شماره 8 نشان داده شده است.
عمق کانونی زمینلرزههای اتفاقافتاده در بازه 30ساله با استفاده از ابزار درونیابی در نرمافزار ArcGIS نسخه 1/7/10 به دست آمده و درصد هر طبقه محاسبه شده است (
تصویر شماره 9).
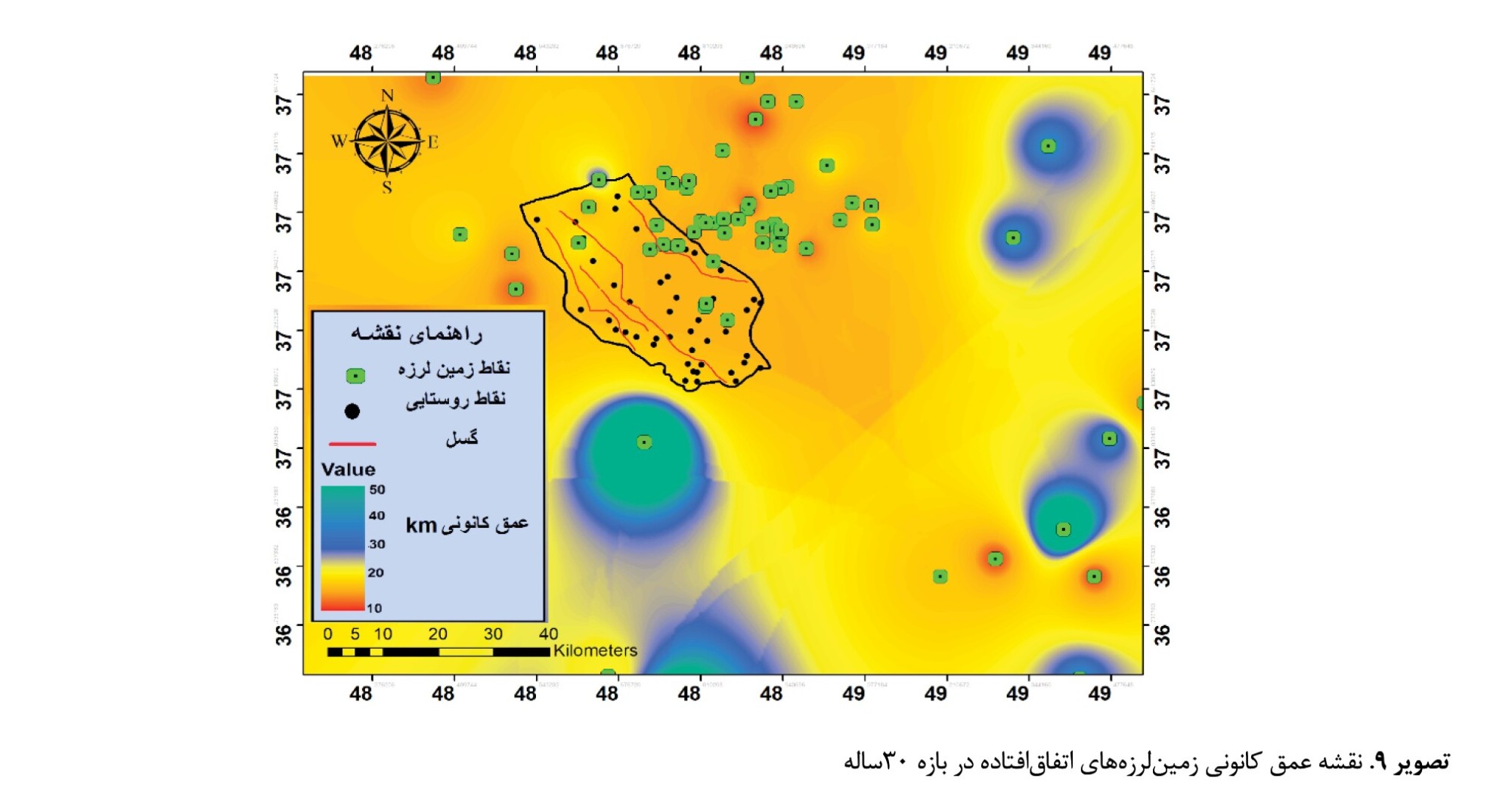
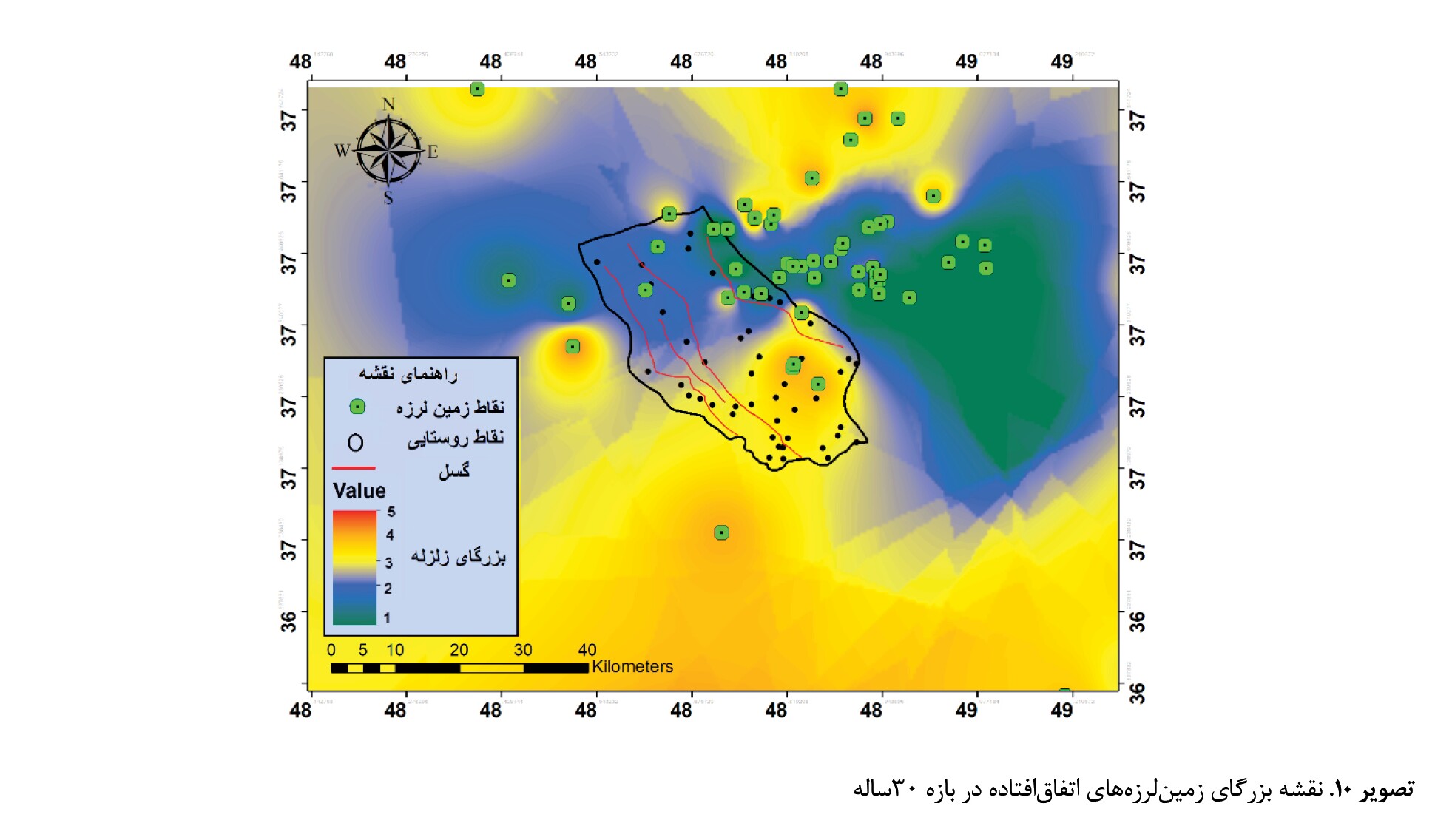
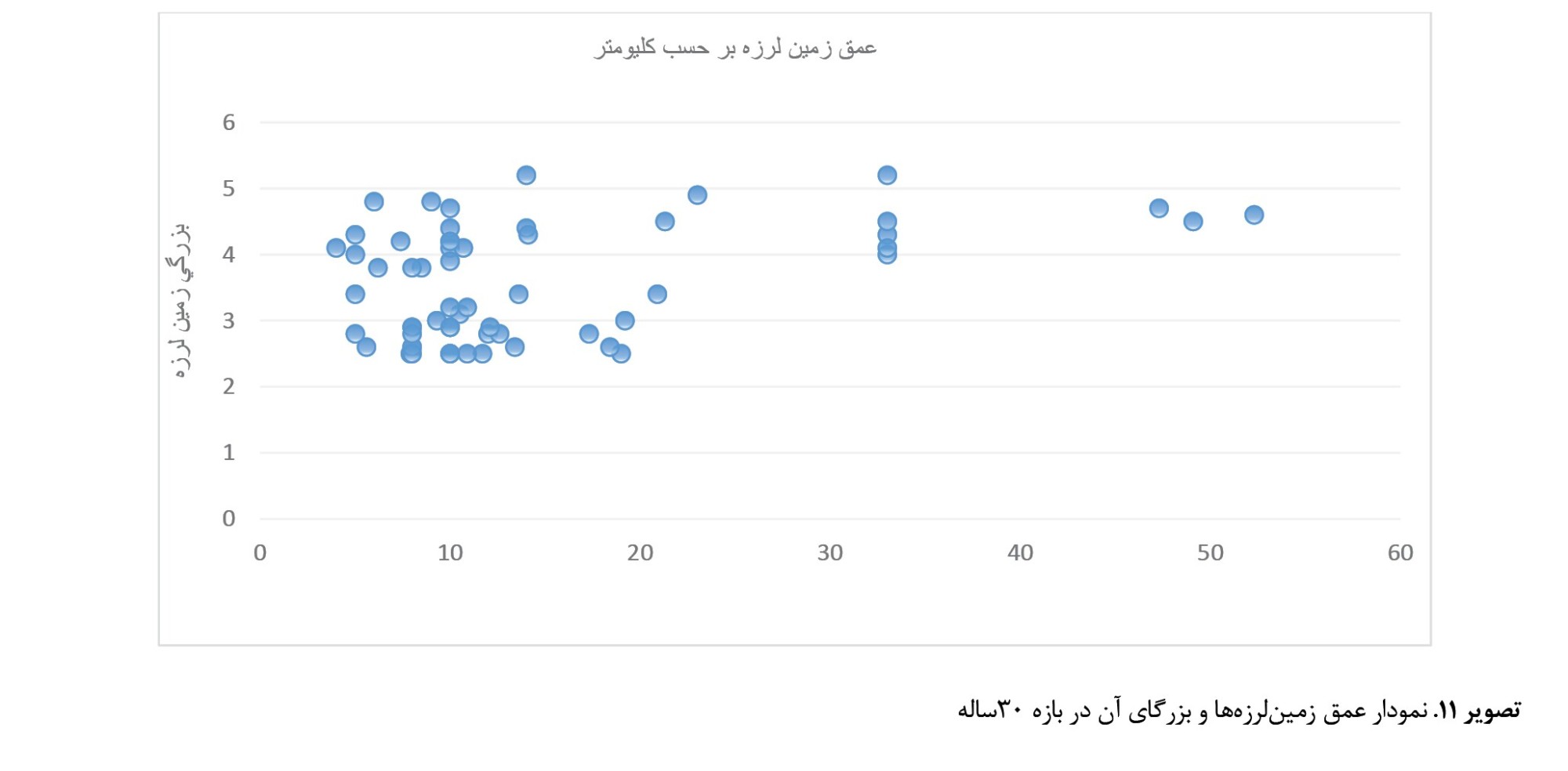
باتوجهبه نقشه مذکور، 60 درصد از زمینلرزههای رخداده در داخل محدوده بخش شاهرود در عمق بین 10 تا 15کیلومتری اتفاق افتاده که دارای عمق پایینی هستند. همچنین 15درصد از زمینلرزهها در داخل محدوده در عمق بین 20 تا 25کیلومتری رخ دادهاند. اما زمینلرزههای خارج از محدوده بهصورت کلی با 25 درصد در عمق بین 30 تا 40 کیلومتر رخ داده است که نسبت به زمینلرزههای داخل محدوده دارای عمق کانونی بالایی است. همچنین نقشه بزرگای زمینلرزههای رخداده در بازی 30ساله که با ابزار درونیابی ایجاد شده، نشان دهنده این بوده است که 20 درصد زمینلرزههای رخداده دارای بزرگای 1 تا 3 ریشتر و 10 درصد زمینلرزهها دارای بزرگای 4 تا 5 ریشتر هستند (
تصاویر شماره 10 و
شماره 11).
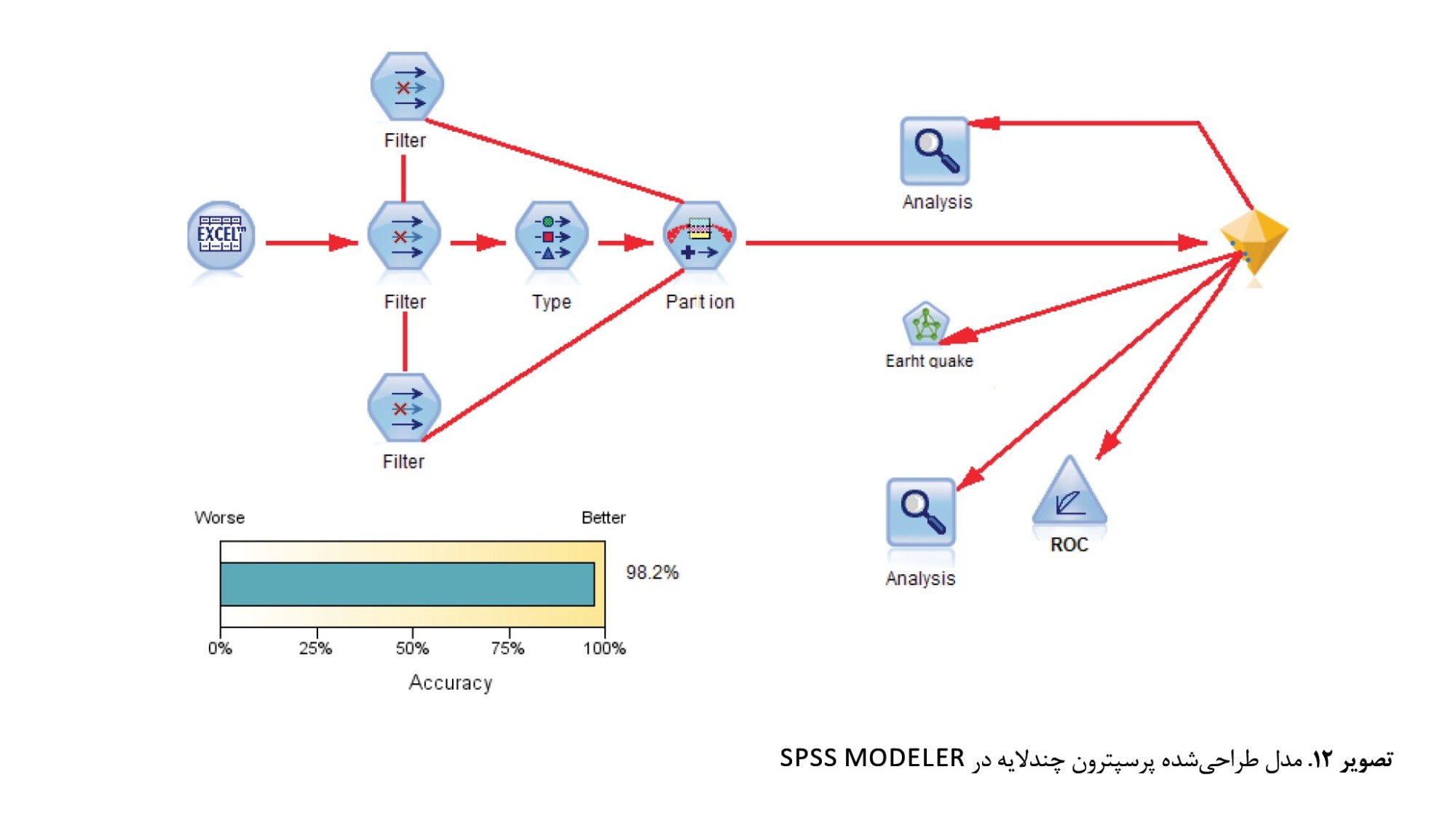
 طراحی مدل برای پهنهبندی مخاطرات دامنهای در نرمافزار spss Modeler
طراحی مدل برای پهنهبندی مخاطرات دامنهای در نرمافزار spss Modeler
فرایند آمادهسازی داده برای ورود به مدل شبکه عصبی مصنوعی از نوع پرسپترون چندلایه، یک فرایند نسبتاً سنگین و پیچیده است. دادههای موردنیاز پیشبینی بزرگای زمینلرزه در وهله اول گردآوری شد. سپس عملیات آنالیز آن برای استخراج بخشهای مورداستفاده در نرمافزار سیستم اطلاعات جغرافیایی انجام شد. اساس کار در پیشبینی با مدل یادشده، براساس مقادیر پیکسلها در هر متغیر موجود برای پیشبینی زمینلرزه است؛ بنابراین روش آمادهسازی دادهها بهصورت پیکسل پایه بود. سپس تمام متغیرها با ترکیب نسبت به یکدیگر تبدیل به یک نقشه رستری واحد شدند که مقادیر پیکسلی آن دربرگیرنده تمام متغیرهای مؤثر بر پیشبینی بزرگای زمینلرزه است. هدف از این ترکیب تصاویر رستری، به دست آوردن مجموعه مقادیر تمام متغیرهای مورداستفاده است. علت این فرایند این است که تمام لایهها و نقشهها در نرمافزار سیستم اطلاعات جغرافیایی ایجاد شوند و بهخاطر اینکه بتوان مقادیر آنها را خارج کرد تا وارد مدل شوند باید فرایند گفتهشده را لحاظ کرد. برای مدل سازی، دادهها بعد از ورود به مدل به ۷۰ درصد دادههای آموزش و ۳۰ درصد دادههای تست شبکه تقسیم شدند که براساس این معیار 70 درصد دادهها برای آموزش شبکه و 30 درصد برای تست در نظر گرفته شد. همچنین برای عامل پیشبینی بزرگای زمینلرزه 5 معیار انتخاب شد که عبارتاند از: 1. عمق زمینلرزه، 2. بزرگای زمینلرزه رخداده، 3. فاصله گسل از نقاط، 4. موقعیت مکانی زمینلرزههای رخداده، 5. طول گسل (
تصاویر شماره 6 تا
10).
در رابطه با دادههای بزرگی و عمق آن از دادههای مناطق نزدیک به محدوده موردمطالعه استفاده شده است که این کار، هم بر کیفیت خروجی دادهها تأثیر دارد و هم به اینکه عامل زمینلرزه بهنحوی است که امواج پخششده آن زیاد بوده و فواصل زیادی را تحت تأثیر خود قرار میدهد. استفاده از دادههای زمینلرزه نزدیک به منطقه سبب شناخت هرچهبهتر الگو و روابط بین زمینلرزهها و پارامترهای دیگر میشود. برای مدل شبکه عصبی مصنوعی، 5 نورون ورودی، 3 نورون میانه و یک نورون خروجی طراحی شده است. همچنین مدل شبکه عصبی برای پایان پردازش و آنالیز خروجی نیازمند در نظر گرفتن معیار توقف است که این عیار خود در مدل شبکه عصبی به سه دسته تقسیم میشود . باتوجهبه اینکه ورودی دادهها دارای ابعاد بزرگی است و جمعاً 2085 پیکسل را پوشش میدهد، برای توقف مدل از معیار خطای آموزش استفاده شد. در این معیار هرگاه مدل به میزان خطای معرفیشده از سوی کاربر برسد، عملیات پردازش متوقف شده و نتایج نشان داده میشود. همچنین نرخ سرعت یادگیری مدل براساس دادههای آموزشی مقدار 0/01 در نظر گرفته شده تا خروجی مدل دارای بیشترین دقت باشد (
جدول شماره 1).
 زمینلرزه
زمینلرزه
براساس اطلاعات بالا بعد از طراحی مدل و تنظیمات شبکه اقدام به وارد کردن دادههای موردنظر و پردازش آن شد و شبکه عصبی مصنوعی پرسپترون چندلایه با 5 نورون ورودی، 3 نورون میانه و یک نورون خروجی با دقت 98/2 درصد ایجادشد که نمایانگر این است که مدل طراحیشده دارای دقت بالایی در پردازش دادهها برای پیشبینی بزرگای زمینلرزه بوده است و نتایج باتوجهبه دقت اولیه دارای اعتبار بالایی است (
تصاویر شماره 12 و
شماره 13).
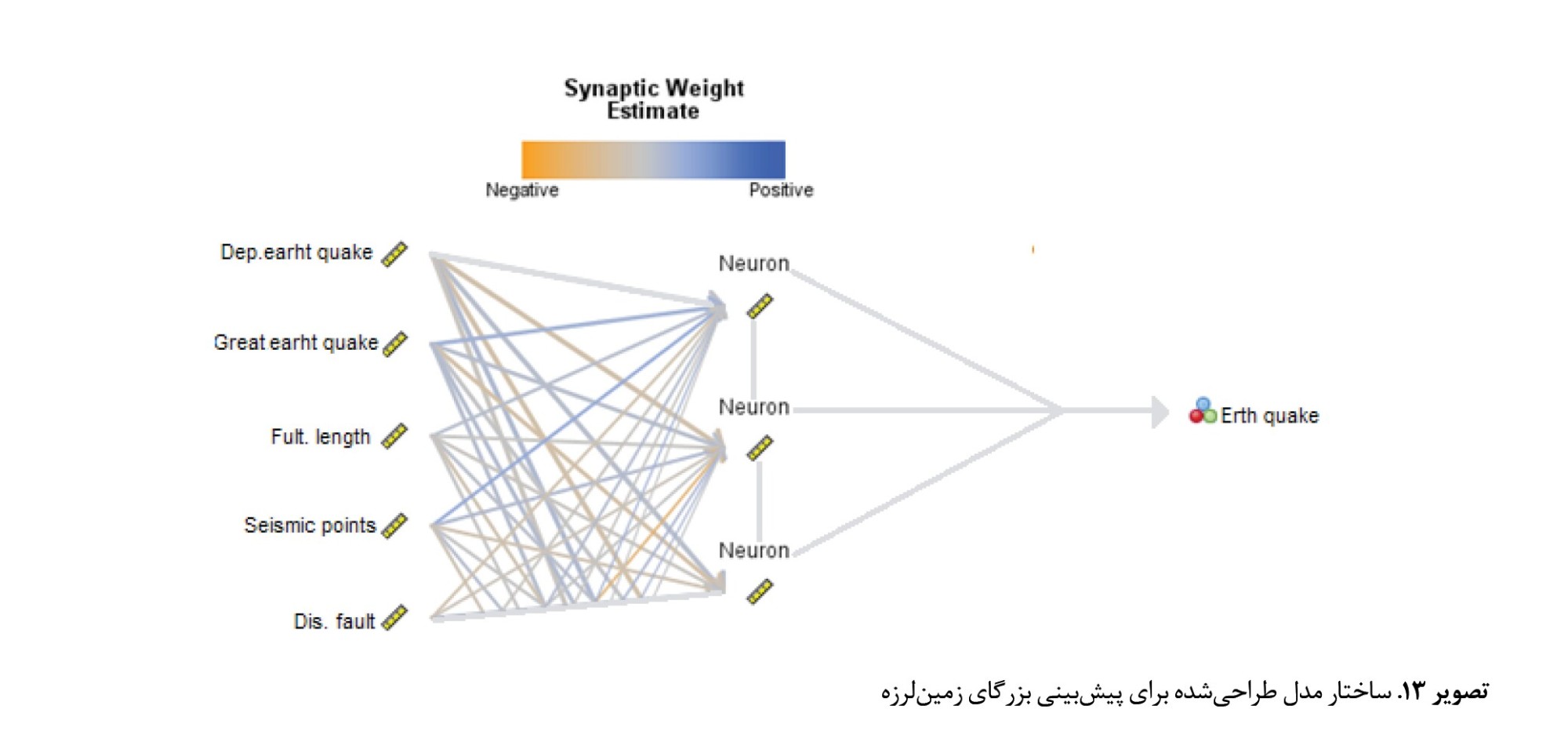
شبکه عصبی پرسپترون چندلایه جهت طراحی نیازمند سه دسته داده آموزشی، آزمایشی و صحتسنجی است. دادههای آموزشی بهمنظور پیدا کردن رابطه بین ورودیها و خروجیهای مشاهدهشده توسط مدل استفاده میشوند. باتوجهبه
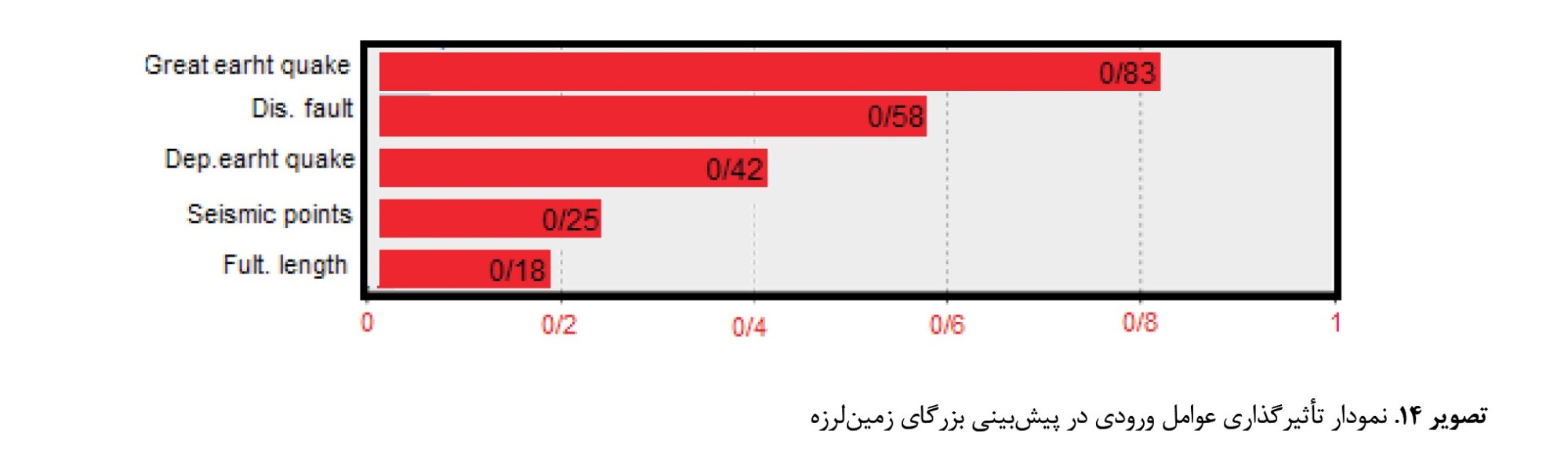
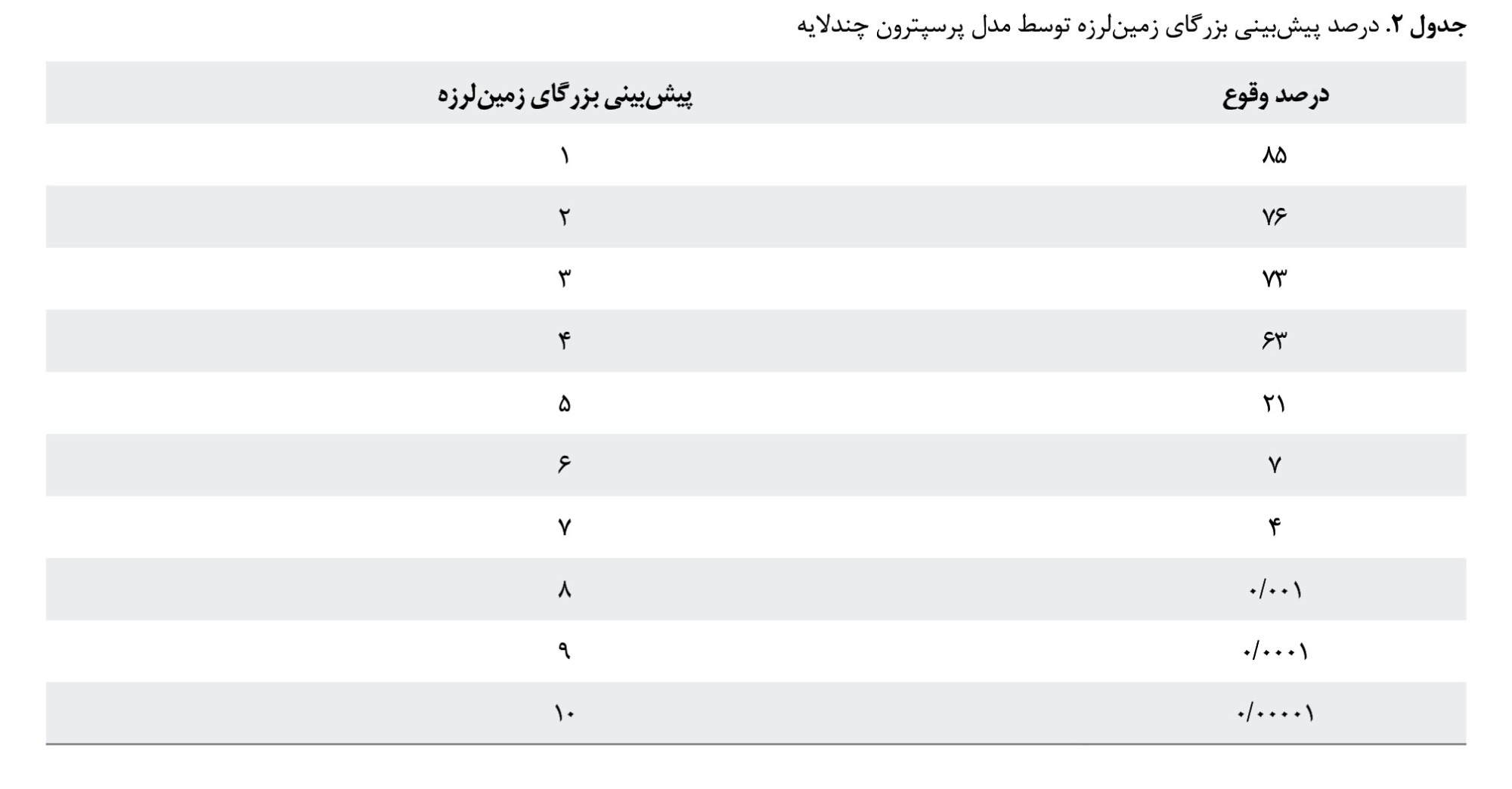
تصویر شماره 14 و
جدول شماره 2، نتایج نشاندهنده این است که مدل پرسپترون چندلایه، بیشترین ارزش تأثیرگذاری را بهترتیب برای لایههای بزرگای زمینلرزه با مقدار 0/83، فاصله از گسل 0/58، عمق کانونی 0/42، همچنین کمترین ارزش تأثیرگذاری را نیز برای عامل نقاط لرزهخیز با مقدار 0/25 و عامل طول گسل 0/18 اختصاص داده است.
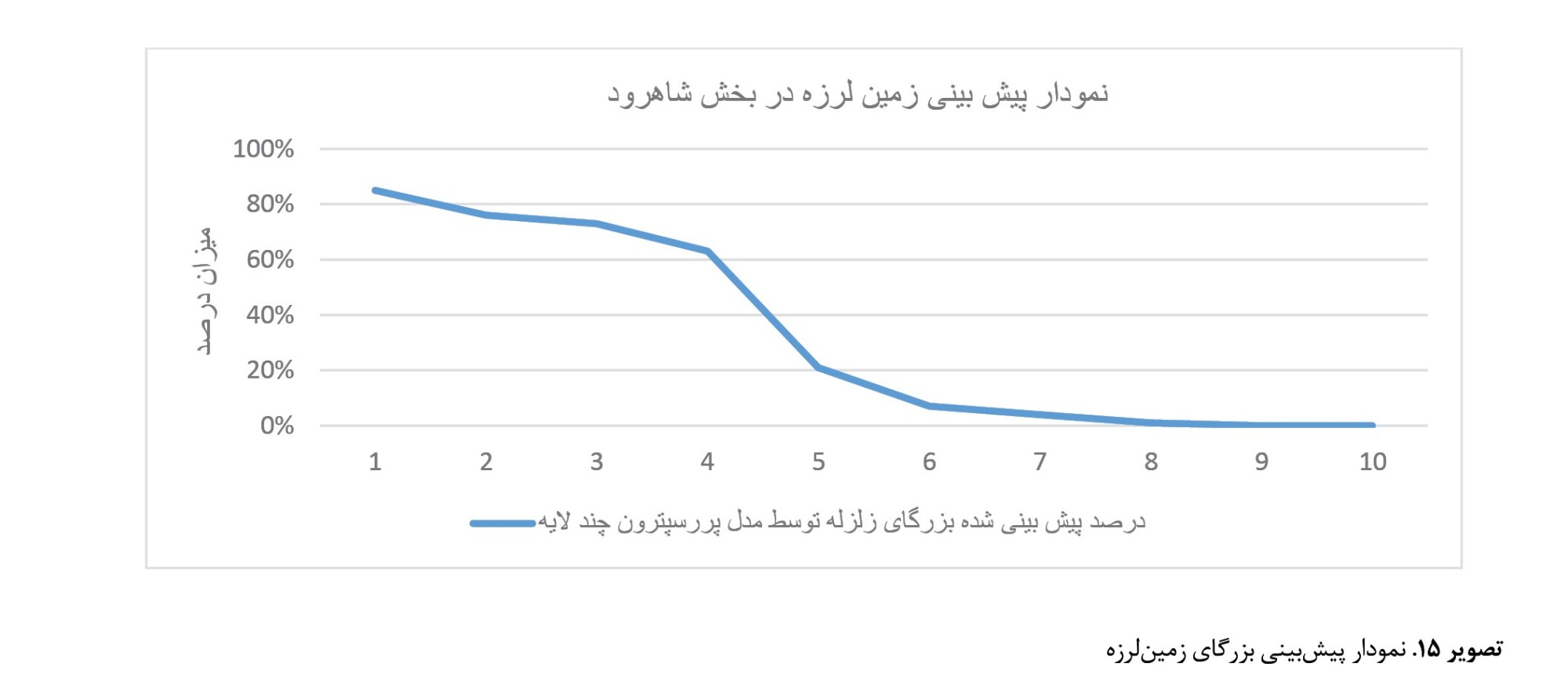
تخصیص مقادیر نهایی توسط مدل صورت میگیرد و برای هر متغیر یک عدد اختصاص داده میشود و کاربر هیچ نوع دخالتی در تعیین مقادیر خروجی ندارد، اما هرچه ورودی دارای کیفیت و دقت و فراوانی بالایی باشد نتایج نهایی درمورد تخصیص وزنها نیز دارای کیفیت و دقت بالاتری خواهد شد. همچنین نتایج اصلی پیشبینی بزرگای زمینلرزه نشاندهنده این است که رخداد زمینلرزه با بزرگای 1 تا 3 ریشتر در منطقه با مجموع 70 درصد دارای احتمال بیشتری است. همچنین پیشبینی وقوع زمینلرزه با بزرگای 4 تا 6 ریشتر با 26 درصد احتمال متوسطی دارد. اما پیشبینی زمینلرزههایی با بزرگای 7 تا 10 ریشتر توسط مدل پرسپترون چندلایه با مجموع 4 درصد دارای احتمال خیلی پایینی است. نتایج بهدستآمده پیشبینی بزرگای زمینلرزه در بازه 30ساله برای بخش شاهرود مدلسازی و اجرا شده است (
تصویر شماره 15).
گرچه بازه 30ساله در پیشبینی بزرگای زمینلرزهها عدد کوچکی است، اما باتوجهبه موجودیت دادهها و نتایج بهدستآمده میتواند یک دید کلی درمورد پیشبینی بزرگای زمینلرزه در منطقه ارائه دهد. همچنین یکی از مزیتهای شبکه عصبی پرسپترون چندلایه این است که برای پیشبینی و طبقهبندی دادههایی که بخش از آنها به هر علتی در دسترس نیست یا جمعآوری آنها دشوار است، کاربرد دارد. به این علت شبکه عصبی پرسپترون چندلایه و سایر مدلهای هوش مصنوعی و یادگیری ماشینی در سالهای اخیر برای پیشبینی عوامل مختلف مورداستفاده قرار گرفتهاند. در این پژوهش نیز بهخاطر رخ ندادن زمینلرزهها با بزرگای بالای 6 ریشتر در بازه 30ساله، قسمتی از دادههای بخش بزرگای زمینلرزه مجهول بوده و وارد مدل شبکه عصبی پرسپترون چندلایه شده است. نکته مهم در رابطه با پیشبینی بزرگای زمینلرزه این است که اگر در رابطه با پیشبینی از یک گروه داده برای ورودی استفاده شود، نتایج آن قابلاستناد نخواهد بود. اما در این پژوهش از دادههای مختلفی برای پیشبینی استفاده شده است که با تشکیل ماتریس و مقایسه برای محاسبه وزن نهایی پارامترهای شبکه استفاده شده و نتایج نهایی ایجاد شده است. بنابراین نتایج نهایی وابسته به کل ورودی مدل است وهرچه دستههای ورودی بیشتر باشد و برای پیشبینی یک متغیر از عوامل مختلف استفاده شود، دقت خروجی مدل نیز افزایش خواهد یافت که در این پژوهش از 5 عامل برای مدلسازی و پیشبینی بزرگای زمینلرزه استفاده شده است.
اعتبارسنجی مدل پرسپترون چندلایه
برای اعتبارسنجی دادهها و نقشه پهنهبندی خطر زمینلغزش از منحنی مشخصه عملکرد گیرنده در رابطه با خروجی دادهها استفاده شد. این منحنی یادشده، هم برای دادههای آموزشی اجرا شده و هم برای دادههای تست شبکه. برای اعتبارسنجی یک مدل در وهله اول باید مرحله آموزش و اعتبارسنجی انجام شود تا میزان ارزش بخش آموزشی معلوم شود. مدلی که در بخش آموزش دارای اعتبار پایینی باشد عموماً در مرحله نهایی نیز دارای دادههای با دقت کمتر خواهد بود (
وهابزاده، 1402). همچنین اعتبارسنجی بخش تست شبکه نیز بهعنوان بخش نهایی در اعتبارسنجی شناخته میشود. برحسب نوع و میزان آموزش کیفیت دادههای خروجی نیز متغیر است. همچنین در بخش تست شبکه نمیتوان از مقادیر سلولی مناطق خطر ریزش استفاده کرد. بنابراین در بخش طراحی مدل، دادهها به 70 درصد آموزش و 30 درصد تست شبکه تقسیم شدند؛ به مثال ساده، نرمافزار در مرحله مدلسازی 30 درصد مقادیر سلولی مناطق ریزشی را نگهداشته و آن را با دادههای آموزشی ترکیب نمیکند و در آخر برای تست شبکه از همین دادههای 30 درصد استفاده میشود. نرمافزار بهصورت خودکار با عمل مقایسه دادههای خروجی و دادههای 30 درصد از طریق نمودار اعتبار نتیجه خروجی را نمایش میدهد (
وهابزاده، 1402).
باتوجهبه منحنی
تصویر شماره 16 که در بخش اول مربوط به قسمت آموزش مدل MLP است، میزان اعتبار نشاندهنده این است که مدل بهخوبی آموزش دیده و پیشبینی آن در خصوص بزرگای زمینلرزه در آینده قابلاعتماد است.
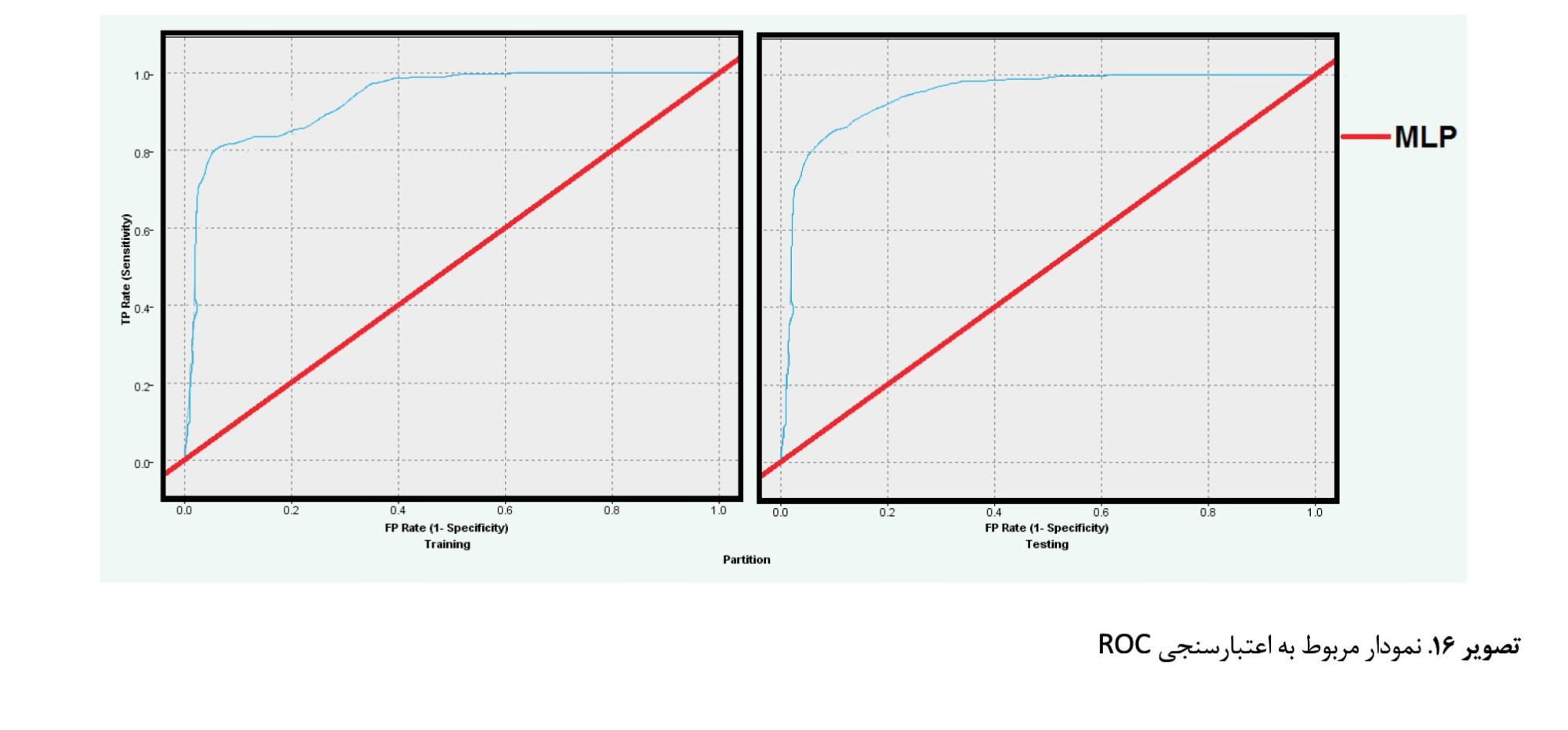
معیار این منحنی بهگونهای است که خطوط رسمشده هرچه دارای فاصله بیشتری از منحنی قرمز اصلی باشد دارای اعتبار بالاتری است. همچنین در این نمودار، منحنی آبی به سمت چپ مایل شده و به سمت بالا روانه شده که این حالت هم نمایانگر اعتبار بالای مدل در بخش آموزش است. بنابراین آموزش صحیح مدل سبب شده نتایج خروجی در بخش تست نیز اعتبار بالا را نشان دهند. بخش آموزش دارای تفاوت اندکی است و ناحیه زیر منحنی عدد 0/911 در بخش آموزش و 0/934 در بخش تست شبکه را نشان میدهد (
جدول شماره 3) که گویای این است که مدل هم در بخش آموزش و هم در بخش تست دارای اعتبار بالایی بوده و در رتبه عالی قرار گرفته و نتایج خروجی آن قابلاعتماد است.
 بحث
بحث
باتوجهبه عملکرد مدل پرسپترون چندلایه در خصوص پیشبینی و تخمین بزرگای زمینلرزه در بخش شاهرود، نتایج نشان داد در مرحله اولیه، پیشبینی مدل بیشترین ارزش تأثیرگذاری را در خصوص بزرگای زمینلرزه به عوامل بزرگای زمینلرزههای رخداده با مقدار 0/83 درصد و برای لایه فاصله از گسل و عمق کانونی زمینلرزههای رخداده بهترتیب با مقدار 0/58 و 0/42 درصدو کمترین ارزش تأثیرگذاری را به عامل نقاط لرزهخیز با مقدار 25/0 درصد و برای عامل طول گسل با مقدار 0/18 درصد اختصاص داده است. در پروسه پیشبینی و تخمین بزرگای زمینلرزه، دادههای مهم لرزهنگاری بسیار مهم هستند؛ چراکه با بررسی و ارزیابی آنها میتوان روابط معنیداری را در خصوص عوامل مختلف کشف کرد. رخداد متوالی زمینلرزهها در ناحیه شرقی بخش شاهرود که بیشتر از 70 درصد آنها در عمق 10 تا 20 کیلومتری و با بزرگای 1 تا 3 ریشتر بوده، نشاندهنده فعال بودن گسل کلور است. همچنین با بررسی سایر نقاط لرزهخیز در داخل منطقه معلوم شده که 70 درصد نقاط در نزدیک گسلها اتفاق افتاده و با فعالیت جنبشی گسلها ارتباط معنیداری دارند. مدل طراحیشده در رابطه با پیشبینی و تخمین بزرگای زمینلرزه با 5 نورون ورودی، 3 نورون میانه و یک نورون خروجی طراحی شده است و نتایج نهایی مدل بعد از آموزش و سنجش میزان اعتبار آن نشان داده که زمینلرزهها با شدت و بزرگای 1 تا 3 ریشتر احتمال وقوع خیلی زیادی دارند و امکان رخداد آنها در مناطق گسله بهویژه گسل کلور خیلی بالاست. گرچه زمینلرزههایی با این شدت و قدرت در رتبه کمخطر طبقهبندی میشوند اما رخداد آنها در عمقهای کم و نزدیک به مناطق مسکونی که بهلحاظ ساخت کیفیت پایین دارند میتواند خسارات جانی و مالی زیادی ایجاد کند. همچنین زمینلرزههایی با بزرگای 4 تا 6 ریشتر با 26 درصد، احتمال وقوع متوسطی دارند. رخداد این زمینلرزهها با قدرت و شدت تعریفشده میتواند خسارات زیادی را در منطقه ایجاد کند. همچنین زمینلرزههایی با قدرت و شدت بالا در حد 7 تا 10 ریشتر قدرت تخریبی خیلی بالایی دارند و احتمال وقوع آنها در منطقه بهندرت و 4 درصد است که نشاندهنده این است که احتمال وقوع آنها پایین است. براساس آمارها و سوابق زمینلرزهها در منطقه نیز وقوع این مدل زمینلرزهها در فواصل زمانی بلندی اتفاق افتاده، اما درصد وقوع زمینلرزههایی با شدت و قدرت خیلی بالا با بزرگای 8 تا 10 ریشتر در منطقه بهشدت پایین است و درصد پیشبینی مدل نیز نزدیک به صفر است که بر درصد احتمال خیلی پایین این مدل زمینلرزه دلالت دارد. مدلهای مبتنی بر هوش مصنوعی که توانایی یادگیری توابع و پارامترهای مختلف را دارند، ابزار مهمی در رابطه با حل مسائل پیچیده شناخته میشوند. مدل پرسپترون چندلایه که بهعلت الگوبرداری از سیستم محاسباتی مغز انسان عملکرد خوبی در این رابطه دارد، عموماً در سطح جهان برای پیشبینی خصوصیات زمینلرزه استفاده میشود. بنابراین استفاده از مدلهای هوش مصنوعی بهویژه مدل پرسپترون چندلایه در خصوص پیشبینی بزرگای زمینلرزه میتواند کمک زیادی در رابطه با شناخت الگو و روابط پیچیده مختلف کند.
نتیجهگیری
برای اعتبارسنجی دادهها و نقشه پهنهبندی خطر زمینلغزش از منحنی ROC دررابطهبا خروجی دادهها استفاده شده است. این منحنی یادشده هم برای دادههای آموزشی و هم برای دادههای تست شبکه اجر شده است. برای اعتبارسنجی یک مدل در وهله اول باید مرحله آموزش و اعتبارسنجی شود تا میزان ارزش بخش آموزشی معلوم شود. مدلی که در بخش آموزش دارای اعتبار پایینی باشد عموماً در مرحله نهایی نیز دادهها دارای دقت کمتری خواهد بود (
وهابزاده، 1402). همچنین اعتبارسنجی بخش تست شبکه نیز بهعنوان بخش نهایی در اعتبارسنجی شناخته میشود. برحسب نوع و میزان آموزش کیفیت دادههای خروجی نیز متغیر است. همچنین در بخش تست شبکه نمیتوان از مقادیر سلولی مناطق خطر ریزش استفاده کرد. بنابراین در بخش طراحی مدل دادهها به 70 درصد آموزش و 30 درصد تست شبکه تقسیم شده است. به مثال ساده نرمافزار در مرحله مدلسازی 30 درصد مقادیر سلولی مناطق ریزشی را نگهداشتِ و آن را با دادههای آموزشی ترکیب نمیکند و در آخر برای تست شبکه از همین دادههای 30 درصد استفاده میشود. نرمافزار بهصورت خودکار با عمل مقایسه دادههای خروجی و دادههای 30 درصد از طریق نمودار اعتبار نتیجه خروجی را نمایش میدهد (
وهابزاده، 1402). باتوجهبه منحنی (
تصویر شماره 8)، در بخش اول مربوط به قسمت آموزش مدل MLP است، میزان اعتبار نشاندهنده این است که مدل بهخوبی آموزشدیده و پیشبینی آن درخصوص بزرگای زمینلرزه در آینده قابلاعتماد است.
معیار این منحنی بهگونه است که خطوط رسمشده هرچه دارای فاصله بیشتری از منحنی قرمز اصلی باشد، دارای اعتبار بالایی است همچنین در نمودار بالا منحنی آبی به سمت چپ مایل شده و به سمت بالا روانه شده که این حالت هم نمایانگر اعتبار بالایی مدل در بخش آموزش است. بنابراین آموزش صحیح مدل سبب شده نتایج خروجی در بخش تست نیز اعتبار بالا را نشان دهند. بخش آموزش دارای تفاوت اندکی است و مقدار AUC عدد 0/911 در بخش آموزش و 0/934 در بخش تست شبکه را نمایش میدهد (
جدول شماره 3) که گویای این است که مدل هم در بخش آموزش و هم در بخش تست دارای اعتبار بالایی بوده و در رتبه عالی قرارگرفته و نتایج خروجی آن قابلاعتماد است.
ملاحظات اخلاقی
پیروی از اصول اخلاق پژوهش
در این مقاله تمام اصول اخالق پژوهش رعایت شده است.
حامی مالی
این پژوهش هیچگونه کمک مالی از سازمانیهای دولتی، خصوصی و غیرانتفاعی دریافت نکرده است.
مشارکت نویسندگان
تمام نویسندگان در آمادهسازی این مقاله مشارکت داشتند.
تعارض منافع
بنابر اظهار نویسندگان، این مقاله تعارض منافع ندارد.
تشکر و قدردانی
از مراکزی چون مرکز لرزهنگاری کشوری و مؤسسه ژئوفیزیک دانشگاه تهران که در جهت انجام این پژوهش با ارائه دادهها و اطلاعات مهم ما را یاری کردند، تشکر و قدردانی میشود.









